import numpy as np
import pandas as pd
import matplotlib
from matplotlib import pyplot as plt
import seaborn as sns
import os
from sklearn import preprocessing
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
import torch
import torch.nn as nn
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
import rasterio as rio
import torchmetrics as tm
from torchinfo import summary
import torchvision
import torchvision.transforms as transformsTransfer Learning and CNNs
Transfer Learning and CNNs
Introduction
In this last section focused on CNNs for scene classification or scene labeling, we will experiment with transfer learning for classifying the EuroSatAllBands dataset. Specifically, we will use a modified ResNet-32 architecture initialized using pre-trained weights from ImageNet. The majority of the code that you will see in this module is not new, so I will keep my explanations brief. As this module demonstrates, once you have learned the key components of implementing deep learning with PyTorch, it is possible to use your knowledge and adapt your or another analyst’s code to a new purpose or problem.
Preparation
This first section is identical to the first section of the Train a CNN module. Here is a quick review of the steps required to prepare the EuroSatAllBands data for input into a CNN architecture designed for scene labeling.
- Import the required libraries. This includes numpy, pandas, matplotlib, seaborn, os, torch, torch.nn, torch.utils.data.dataset, torch.utils.data, rasterio, torchmetrics, torchinfo, torchvision, and torchvision.transforms. I also import some specific assessment functions from scikit-learn.
- Set the device variable to the GPU if one is available.
- Set the folder path to the data to the folder variable.
- Read in the data tables of image chips using pandas. Here, I am also augmenting the file path since I am working on a different computer with a different directory structure.
- Define a DataSet subclass to obtain the band statistics.
- Instantiate a DataSet for the training set.
- Define a DataLoader for the DataSet.
- Define a function to calculate the pixel-level band means and standard deviations.
- Calculate the band means and standard deviations.
- Define a DataSet subclass for use in the training and validation process that accepts a DataFrame containing the information for each image chip, the band means and standard deviations, and transforms.
- Further prepare the band means and standard deviations to create tensors with the same shape as the input image chips (10, 64, 64).
- Define transforms for the training data. Here, I am using random horizontal and vertical flips.
- Instantiate an instance of the DataSet class for the training data that uses the defined transforms and an instance of the validation data that does not apply the transforms.
- Define the DataLoader for the training and validation data. I am using a mini-batch size of 32 here as this worked on my hardware. You may need to change this depending on your system and GPU specifications.
- Perform checks to make sure the mini-batch shapes and data types are correct. Also, check a single image chip.
- Define a function to display a batch of images and their associated labels.
- Visualize a batch of images and their associated labels.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)cuda:0folder = "C:/datasets/archive/EuroSATallBands/"train = pd.read_csv(folder+"mytrain.csv")
test = pd.read_csv(folder+"mytest.csv")
val = pd.read_csv(folder+"myval.csv")class EuroSat(Dataset):
def __init__(self, df):
super().__init__
self.df = df
def __getitem__(self, idx):
image_name = self.df.iloc[idx, 1]
label = self.df.iloc[idx, 3]
label = np.array(label)
source = rio.open(image_name)
image = source.read()
source.close()
image = image.astype('float32')
image = image[[1,2,3,4,5,6,7,8,11,12], :, :]
image = torch.from_numpy(image)
label = torch.from_numpy(label)
label = label.long()
return image, label
def __len__(self):
return len(self.df)trainDS = EuroSat(train)
print(len(trainDS))16558trainDL = torch.utils.data.DataLoader(trainDS, batch_size=32, shuffle=True, sampler=None,
num_workers=0, pin_memory=False, drop_last=False)#https://www.binarystudy.com/2021/04/how-to-calculate-mean-standard-deviation-images-pytorch.html
def batch_mean_and_sd(loader, inChn):
cnt = 0
fst_moment = torch.empty(inChn)
snd_moment = torch.empty(inChn)
for images, _ in loader:
b, c, h, w = images.shape
nb_pixels = b * h * w
sum_ = torch.sum(images, dim=[0, 2, 3])
sum_of_square = torch.sum(images ** 2,
dim=[0, 2, 3])
fst_moment = (cnt * fst_moment + sum_) / (cnt + nb_pixels)
snd_moment = (cnt * snd_moment + sum_of_square) / (cnt + nb_pixels)
cnt += nb_pixels
mean, std = fst_moment, torch.sqrt(snd_moment - fst_moment ** 2)
return mean,stdband_stats = batch_mean_and_sd(trainDL, 10)class EuroSat(Dataset):
def __init__(self, df, mnImg, sdImg, transform):
self.df = df
self.mnImg = mnImg
self.sdImg = sdImg
self.transform = transform
def __getitem__(self, idx):
image_name = self.df.iloc[idx, 1]
label = self.df.iloc[idx, 3]
label = np.array(label)
source = rio.open(image_name)
image = source.read()
source.close()
image = image[[1,2,3,4,5,6,7,8,11,12], :, :]
image = np.subtract(image, self.mnImg)
image = np.divide(image, self.sdImg)
image = image.astype('float32')
image = torch.from_numpy(image)
label = torch.from_numpy(label)
label = label.long()
if self.transform is not None:
image = self.transform(image)
return image, label
def __len__(self):
return len(self.df)bndMns = np.array(band_stats[0].tolist())
bndSDs = np.array(band_stats[1].tolist())mnImg = np.repeat(bndMns[0], 64*64).reshape((64,64,1))
for b in range(1,len(bndMns)):
mnImg2 = np.repeat(bndMns[b], 64*64).reshape((64,64,1))
mnImg = np.dstack([mnImg, mnImg2])
mnImg = np.transpose(mnImg, (2,0,1))
sdImg = np.repeat(bndSDs[0], 64*64).reshape((64,64,1))
for b in range(1,len(bndSDs)):
sdImg2 = np.repeat(bndSDs[b], 64*64).reshape((64,64,1))
sdImg = np.dstack([sdImg, sdImg2])
sdImg = np.transpose(sdImg, (2,0,1))
print(mnImg.shape)(10, 64, 64)print(sdImg.shape)(10, 64, 64)myTransforms = transforms.Compose(
[transforms.RandomHorizontalFlip(p=0.3),
transforms.RandomVerticalFlip(p=0.3),]
)trainDS = EuroSat(train, mnImg, sdImg, transform=myTransforms)
valDS = EuroSat(val, mnImg, sdImg, transform=None)trainDL = torch.utils.data.DataLoader(trainDS, batch_size=32, shuffle=True, sampler=None,
num_workers=0, pin_memory=False, drop_last=True)
valDL = torch.utils.data.DataLoader(valDS, batch_size=32, shuffle=False, sampler=None,
num_workers=0, pin_memory=False, drop_last=True)batch = next(iter(trainDL))
images, labels = batch
print(f'Batch Image Shape: {images.shape}, Batch Label Shape: {labels.shape}')Batch Image Shape: torch.Size([32, 10, 64, 64]), Batch Label Shape: torch.Size([32])print(f'Batch Image Data Type: {images.dtype}, Batch Label Data Type: {labels.dtype}')Batch Image Data Type: torch.float32, Batch Label Data Type: torch.int64print(f'Batch Image Band Means: {torch.mean(images, dim=(0,2,3))}')Batch Image Band Means: tensor([-0.0982, -0.1131, -0.0339, -0.0889, -0.0830, -0.0673, -0.0761, -0.2410,
0.0355, -0.0690])print(f'Batch Label Minimum: {torch.min(labels, dim=0)}, Batch Label Maximum: {torch.max(labels, dim=0)}')Batch Label Minimum: torch.return_types.min(
values=tensor(0),
indices=tensor(0)), Batch Label Maximum: torch.return_types.max(
values=tensor(9),
indices=tensor(2))testImg = images[1]
testMsk = labels[1]
print(f'Image Shape: {testImg.shape}, Label Shape: {testMsk.shape}')Image Shape: torch.Size([10, 64, 64]), Label Shape: torch.Size([])print(f'Image Data Type: {testImg.dtype}, Label Data Type: {testMsk.dtype}')Image Data Type: torch.float32, Label Data Type: torch.int64def img_display(img, mnImg, sdImg):
img = np.multiply(img, sdImg)
img = np.add(img, mnImg)
image_vis = img[[2,1,0],:,:]
image_vis = image_vis.permute(1,2,0)
image_vis = (image_vis.numpy()/4000)*255
image_vis = image_vis.astype('uint8')
return image_vis
batch = next(iter(trainDL))
images, labels = batch
cover_types = {0: 'Annual Crop',
1: 'Forest',
2: 'Herb Veg',
3: 'Highway',
4: 'Industrial',
5: 'Pasture',
6: 'Perm Crop',
7: 'Residential',
8: 'River',
9: 'SeaLake'}fig, axis = plt.subplots(4, 8, figsize=(15, 10))
for i, ax in enumerate(axis.flat):
with torch.no_grad():
image, label = images[i], labels[i]
ax.imshow(img_display(image, mnImg, sdImg)) # add image
ax.set(title = f"{cover_types[label.item()]}") # add label
ax.axis('off')<matplotlib.image.AxesImage object at 0x000002985C4EDF10>
[Text(0.5, 1.0, 'Residential')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x000002985C522510>
[Text(0.5, 1.0, 'Residential')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x00000298832C8A40>
[Text(0.5, 1.0, 'SeaLake')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029881373B60>
[Text(0.5, 1.0, 'Residential')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882B343E0>
[Text(0.5, 1.0, 'Residential')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882B34290>
[Text(0.5, 1.0, 'Annual Crop')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882AE9AF0>
[Text(0.5, 1.0, 'Herb Veg')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882F95160>
[Text(0.5, 1.0, 'Pasture')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882BEA690>
[Text(0.5, 1.0, 'Highway')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882E13050>
[Text(0.5, 1.0, 'Highway')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882E37110>
[Text(0.5, 1.0, 'River')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882E73500>
[Text(0.5, 1.0, 'River')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029881371F10>
[Text(0.5, 1.0, 'Highway')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882EF87D0>
[Text(0.5, 1.0, 'Perm Crop')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882F2C920>
[Text(0.5, 1.0, 'SeaLake')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882B8D2B0>
[Text(0.5, 1.0, 'Herb Veg')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882F959A0>
[Text(0.5, 1.0, 'Highway')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882FC1D00>
[Text(0.5, 1.0, 'Perm Crop')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882FFD640>
[Text(0.5, 1.0, 'Forest')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x000002988326ACC0>
[Text(0.5, 1.0, 'Industrial')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029883057500>
[Text(0.5, 1.0, 'Forest')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882F5F920>
[Text(0.5, 1.0, 'Residential')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x00000298830DC4A0>
[Text(0.5, 1.0, 'SeaLake')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029883298530>
[Text(0.5, 1.0, 'Forest')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x000002988310AF30>
[Text(0.5, 1.0, 'Highway')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882FC3C50>
[Text(0.5, 1.0, 'Industrial')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882B63EF0>
[Text(0.5, 1.0, 'SeaLake')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x00000298831D46B0>
[Text(0.5, 1.0, 'Perm Crop')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x00000298832089B0>
[Text(0.5, 1.0, 'Perm Crop')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029882E73C20>
[Text(0.5, 1.0, 'Perm Crop')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x00000298832697F0>
[Text(0.5, 1.0, 'Perm Crop')]
(-0.5, 63.5, 63.5, -0.5)
<matplotlib.image.AxesImage object at 0x0000029883299F40>
[Text(0.5, 1.0, 'Herb Veg')]
(-0.5, 63.5, 63.5, -0.5)plt.show()
Instantiate Pre-trained Model
The next set of code comes from the prior modules associated with CNN architectures. I first define a function to freeze weights. I next define a function to instantiate a ResNet model. This function allows the user to select a ResNet architecture (“18”, “34”, “50”, “101”, or “152”), the number of input channels, the number of classes being differentiated, whether or not to freeze the parameters/weights associated with the convolutional component of the model, and whether or not to use the pre-trained weights from ImageNet.
I instantiate a model instance using the defined function. I will use a ResNet-34 architecture that expects 10 input channels, differentiates 10 classes, does not have any weights frozen (i.e., all weights will be able to be updated), and that uses pre-trained weights from ImageNet. So, this model will be initialized using the ImageNet weights, other than the first convolutional layer and batch normalization layer and the fully connected layer at the end of the model. However, all weights will be trainable. This is because this problem is very different from the ImageNet use case. Thus, it is expected that the parameters/weights learned from ImageNet within the convolutional component of the model will need to be updated to allow the model to learn spatial patterns useful for this specific problem.
Once the model is initialized, I summarize it using torchinfo and the mini-batch size and tensor shape of the EuroSatAllBands dataset: (32,10,64,64). This model has > 21 million trainable parameters. Since no parameters/weights were frozen, there are no non-trainable parameters.
#https://pytorch.org/tutorials/beginner/finetuning_torchvision_models_tutorial.html
def set_parameter_requires_grad(model, freeze=True):
if freeze == True:
for param in model.parameters():
param.requires_grad = False# https://stackoverflow.com/questions/62629114/how-to-modify-resnet-50-with-4-channels-as-input-using-pre-trained-weights-in-py
# https://discuss.pytorch.org/t/transfer-learning-usage-with-different-input-size/20744
def initialize_model(resNet, nChn, nCls, freeze=True, pretrained=True):
if resNet == "18":
model = torchvision.models.resnet18(pretrained=pretrained)
elif resNet == "34":
model = torchvision.models.resnet34(pretrained=pretrained)
elif resNet == "50":
model = torchvision.models.resnet50(pretrained=pretrained)
elif resNet == "101":
model = torchvision.models.resnet101(pretrained=pretrained)
elif resNet == "152":
model = torchvision.models.resnet152(pretrained=pretrained)
else:
model = torchvision.models.resnet34(pretrained=pretrained)
if pretrained == True:
set_parameter_requires_grad(model, freeze)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, nCls)
if nChn != 3:
model.conv1 = nn.Conv2d(nChn, 64, kernel_size=7, stride=2, padding=3, bias=False)
model.bn1 = nn.BatchNorm2d(64)
return modelmodel = initialize_model(resNet="34", nChn=10, nCls=10, freeze=False, pretrained=True).to(device)summary(model, (32, 10, 64, 64))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [32, 10] --
├─Conv2d: 1-1 [32, 64, 32, 32] 31,360
├─BatchNorm2d: 1-2 [32, 64, 32, 32] 128
├─ReLU: 1-3 [32, 64, 32, 32] --
├─MaxPool2d: 1-4 [32, 64, 16, 16] --
├─Sequential: 1-5 [32, 64, 16, 16] --
│ └─BasicBlock: 2-1 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-1 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-2 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-3 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-4 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-5 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-6 [32, 64, 16, 16] --
│ └─BasicBlock: 2-2 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-7 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-8 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-9 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-10 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-11 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-12 [32, 64, 16, 16] --
│ └─BasicBlock: 2-3 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-13 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-14 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-15 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-16 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-17 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-18 [32, 64, 16, 16] --
├─Sequential: 1-6 [32, 128, 8, 8] --
│ └─BasicBlock: 2-4 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-19 [32, 128, 8, 8] 73,728
│ │ └─BatchNorm2d: 3-20 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-21 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-22 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-23 [32, 128, 8, 8] 256
│ │ └─Sequential: 3-24 [32, 128, 8, 8] 8,448
│ │ └─ReLU: 3-25 [32, 128, 8, 8] --
│ └─BasicBlock: 2-5 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-26 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-27 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-28 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-29 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-30 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-31 [32, 128, 8, 8] --
│ └─BasicBlock: 2-6 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-32 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-33 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-34 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-35 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-36 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-37 [32, 128, 8, 8] --
│ └─BasicBlock: 2-7 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-38 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-39 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-40 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-41 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-42 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-43 [32, 128, 8, 8] --
├─Sequential: 1-7 [32, 256, 4, 4] --
│ └─BasicBlock: 2-8 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-44 [32, 256, 4, 4] 294,912
│ │ └─BatchNorm2d: 3-45 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-46 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-47 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-48 [32, 256, 4, 4] 512
│ │ └─Sequential: 3-49 [32, 256, 4, 4] 33,280
│ │ └─ReLU: 3-50 [32, 256, 4, 4] --
│ └─BasicBlock: 2-9 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-51 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-52 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-53 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-54 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-55 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-56 [32, 256, 4, 4] --
│ └─BasicBlock: 2-10 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-57 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-58 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-59 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-60 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-61 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-62 [32, 256, 4, 4] --
│ └─BasicBlock: 2-11 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-63 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-64 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-65 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-66 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-67 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-68 [32, 256, 4, 4] --
│ └─BasicBlock: 2-12 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-69 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-70 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-71 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-72 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-73 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-74 [32, 256, 4, 4] --
│ └─BasicBlock: 2-13 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-75 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-76 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-77 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-78 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-79 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-80 [32, 256, 4, 4] --
├─Sequential: 1-8 [32, 512, 2, 2] --
│ └─BasicBlock: 2-14 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-81 [32, 512, 2, 2] 1,179,648
│ │ └─BatchNorm2d: 3-82 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-83 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-84 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-85 [32, 512, 2, 2] 1,024
│ │ └─Sequential: 3-86 [32, 512, 2, 2] 132,096
│ │ └─ReLU: 3-87 [32, 512, 2, 2] --
│ └─BasicBlock: 2-15 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-88 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-89 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-90 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-91 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-92 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-93 [32, 512, 2, 2] --
│ └─BasicBlock: 2-16 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-94 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-95 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-96 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-97 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-98 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-99 [32, 512, 2, 2] --
├─AdaptiveAvgPool2d: 1-9 [32, 512, 1, 1] --
├─Linear: 1-10 [32, 10] 5,130
==========================================================================================
Total params: 21,311,754
Trainable params: 21,311,754
Non-trainable params: 0
Total mult-adds (Units.GIGABYTES): 10.29
==========================================================================================
Input size (MB): 5.24
Forward/backward pass size (MB): 156.24
Params size (MB): 85.25
Estimated Total Size (MB): 246.73
==========================================================================================
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [32, 10] --
├─Conv2d: 1-1 [32, 64, 32, 32] 31,360
├─BatchNorm2d: 1-2 [32, 64, 32, 32] 128
├─ReLU: 1-3 [32, 64, 32, 32] --
├─MaxPool2d: 1-4 [32, 64, 16, 16] --
├─Sequential: 1-5 [32, 64, 16, 16] --
│ └─BasicBlock: 2-1 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-1 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-2 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-3 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-4 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-5 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-6 [32, 64, 16, 16] --
│ └─BasicBlock: 2-2 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-7 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-8 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-9 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-10 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-11 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-12 [32, 64, 16, 16] --
│ └─BasicBlock: 2-3 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-13 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-14 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-15 [32, 64, 16, 16] --
│ │ └─Conv2d: 3-16 [32, 64, 16, 16] 36,864
│ │ └─BatchNorm2d: 3-17 [32, 64, 16, 16] 128
│ │ └─ReLU: 3-18 [32, 64, 16, 16] --
├─Sequential: 1-6 [32, 128, 8, 8] --
│ └─BasicBlock: 2-4 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-19 [32, 128, 8, 8] 73,728
│ │ └─BatchNorm2d: 3-20 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-21 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-22 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-23 [32, 128, 8, 8] 256
│ │ └─Sequential: 3-24 [32, 128, 8, 8] 8,448
│ │ └─ReLU: 3-25 [32, 128, 8, 8] --
│ └─BasicBlock: 2-5 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-26 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-27 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-28 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-29 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-30 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-31 [32, 128, 8, 8] --
│ └─BasicBlock: 2-6 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-32 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-33 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-34 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-35 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-36 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-37 [32, 128, 8, 8] --
│ └─BasicBlock: 2-7 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-38 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-39 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-40 [32, 128, 8, 8] --
│ │ └─Conv2d: 3-41 [32, 128, 8, 8] 147,456
│ │ └─BatchNorm2d: 3-42 [32, 128, 8, 8] 256
│ │ └─ReLU: 3-43 [32, 128, 8, 8] --
├─Sequential: 1-7 [32, 256, 4, 4] --
│ └─BasicBlock: 2-8 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-44 [32, 256, 4, 4] 294,912
│ │ └─BatchNorm2d: 3-45 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-46 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-47 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-48 [32, 256, 4, 4] 512
│ │ └─Sequential: 3-49 [32, 256, 4, 4] 33,280
│ │ └─ReLU: 3-50 [32, 256, 4, 4] --
│ └─BasicBlock: 2-9 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-51 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-52 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-53 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-54 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-55 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-56 [32, 256, 4, 4] --
│ └─BasicBlock: 2-10 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-57 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-58 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-59 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-60 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-61 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-62 [32, 256, 4, 4] --
│ └─BasicBlock: 2-11 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-63 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-64 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-65 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-66 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-67 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-68 [32, 256, 4, 4] --
│ └─BasicBlock: 2-12 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-69 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-70 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-71 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-72 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-73 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-74 [32, 256, 4, 4] --
│ └─BasicBlock: 2-13 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-75 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-76 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-77 [32, 256, 4, 4] --
│ │ └─Conv2d: 3-78 [32, 256, 4, 4] 589,824
│ │ └─BatchNorm2d: 3-79 [32, 256, 4, 4] 512
│ │ └─ReLU: 3-80 [32, 256, 4, 4] --
├─Sequential: 1-8 [32, 512, 2, 2] --
│ └─BasicBlock: 2-14 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-81 [32, 512, 2, 2] 1,179,648
│ │ └─BatchNorm2d: 3-82 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-83 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-84 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-85 [32, 512, 2, 2] 1,024
│ │ └─Sequential: 3-86 [32, 512, 2, 2] 132,096
│ │ └─ReLU: 3-87 [32, 512, 2, 2] --
│ └─BasicBlock: 2-15 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-88 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-89 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-90 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-91 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-92 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-93 [32, 512, 2, 2] --
│ └─BasicBlock: 2-16 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-94 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-95 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-96 [32, 512, 2, 2] --
│ │ └─Conv2d: 3-97 [32, 512, 2, 2] 2,359,296
│ │ └─BatchNorm2d: 3-98 [32, 512, 2, 2] 1,024
│ │ └─ReLU: 3-99 [32, 512, 2, 2] --
├─AdaptiveAvgPool2d: 1-9 [32, 512, 1, 1] --
├─Linear: 1-10 [32, 10] 5,130
==========================================================================================
Total params: 21,311,754
Trainable params: 21,311,754
Non-trainable params: 0
Total mult-adds (Units.GIGABYTES): 10.29
==========================================================================================
Input size (MB): 5.24
Forward/backward pass size (MB): 156.24
Params size (MB): 85.25
Estimated Total Size (MB): 246.73
==========================================================================================I am now ready to train the model. I first instantiate an instance of the AdamW optimizer with the default learning rate. I also instantiate the loss metric (cross entropy (CE) loss) and the overall accuracy, class-aggregated, macro-averaged F1-score, and Cohen’s Kappa assessment metrics provided by torchmetrics.
I will train the model for a total of 50 epochs. As I did in the Train a CNN module, I will only save a model to disk if the aggregated F1-score calculated for the validation data improves.
optimizer = torch.optim.AdamW(model.parameters())
criterion = nn.CrossEntropyLoss().to(device)
acc = tm.Accuracy(task="multiclass", num_classes=10).to(device)
f1 = tm.F1Score(task="multiclass", num_classes=10, average="macro").to(device)
kappa = tm.CohenKappa(task="multiclass", num_classes=10).to(device)epochs = 50
saveFolder = "C:/datasets/eurosat_resnet_models/"The training loop is the same as the one used in the Train a CNN module. Here is a review of the key components.
- I must iterate over the epochs and the training mini-batches.
- Backpropagation and an optimization step will be performed after each training mini-batch is processed.
- The validation data will be predicted after each complete iteration over the training data (i.e., one training epoch).
- I am saving the training and validation losses and assessment metrics to list objects.
- A running loss is maintained for each epoch then divided by the number of epochs to obtain an average loss per epoch.
- Metrics are aggregated across batches using the compute() and reset() methods from torchmetrics.
- A model is only being saved to disk if the class-aggregated F1-score for the validation samples improves.
If you decide to run this model, it will likely take several hours to execute. On my machine it took ~3 hours to train for 50 epochs using one GPU and a mini-atch size of 32. If you do not want to run the training loop, a model file has been provided.
eNum = []
t_loss = []
t_acc = []
t_f1 = []
t_kappa = []
v_loss = []
v_acc = []
v_f1 = []
v_kappa = []
f1VMax = 0.0
# Loop over epochs
for epoch in range(1, epochs+1):
model.train()
#Initiate running loss for epoch
running_loss = 0.0
# Loop over training batches
for batch_idx, (inputs, targets) in enumerate(trainDL):
# Get data and move to device
inputs, targets = inputs.to(device), targets.to(device)
# Clear gradients
optimizer.zero_grad()
# Predict data
outputs = model(inputs)
# Calculate loss
loss = criterion(outputs, targets)
# Calculate metrics
accT = acc(outputs, targets)
f1T = f1(outputs, targets)
kappaT = kappa(outputs, targets)
# Backpropagate
loss.backward()
# Update parameters
optimizer.step()
#Update running with batch results
running_loss += loss.item()
# Accumulate loss and metrics at end of training epoch
epoch_loss = running_loss/len(trainDL)
accT = acc.compute()
f1T = f1.compute()
kappaT = kappa.compute()
# Print Losses and metrics at end of training epoch
print(f'Epoch: {epoch}, Training Loss: {epoch_loss:.4f}, Training Accuracy: {accT:.4f}, Training F1: {f1T:.4f}, Training Kappa: {kappaT:.4f}')
# Append results
eNum.append(epoch)
t_loss.append(epoch_loss)
t_acc.append(accT.detach().cpu().numpy())
t_f1.append(f1T.detach().cpu().numpy())
t_kappa.append(kappaT.detach().cpu().numpy())
# Reset metrics
acc.reset()
f1.reset()
kappa.reset()
#Set model in evaluation model
model.eval()
# loop over validation batches
with torch.no_grad():
#Initialize running validation loss
running_loss_v = 0.0
for batch_idx, (inputs, targets) in enumerate(valDL):
# Get data and move to device
inputs, targets = inputs.to(device), targets.to(device)
# Predict data
outputs = model(inputs)
# Calculate validation loss
loss_v = criterion(outputs, targets)
#Update running with batch results
running_loss_v += loss_v.item()
# Calculate metrics
accV = acc(outputs, targets)
f1V = f1(outputs, targets)
kappaV = kappa(outputs, targets)
#Accumulate loss and metrics at end of validation epoch
epoch_loss_v = running_loss_v/len(valDL)
accV = acc.compute()
f1V = f1.compute()
kappaV = kappa.compute()
# Print validation loss and metrics
print(f'Validation Loss: {epoch_loss_v:.4f}, Validation Accuracy: {accV:.4f}, Validation F1: {f1V:.4f}, Validation Kappa: {kappaV:.4f}')
# Append results
v_loss.append(epoch_loss_v)
v_acc.append(accV.detach().cpu().numpy())
v_f1.append(f1V.detach().cpu().numpy())
v_kappa.append(kappaV.detach().cpu().numpy())
# Reset metrics
acc.reset()
f1.reset()
kappa.reset()
# Save model if validation F1-score improves
f1V2 = f1V.detach().cpu().numpy()
if f1V2 > f1VMax:
f1VMax = f1V2
torch.save(model.state_dict(), saveFolder + 'eurosat_model.pt')
print(f'Model saved for epoch {epoch}.')Once the training loop executes, I next explore the training process by merging all of the saved losses and metrics into a single DataFrame. I then save this DataFrame to disk as a CSV file. I plot the training and validation losses along with the class-aggregated F1-score for the training and validation data.
Generally, these graphs suggest that the learning process progressed as expected. There is no evidence of overfitting to the training data.
SeNum = pd.Series(eNum, name="epoch")
St_loss = pd.Series(t_loss, name="training_loss")
St_acc = pd.Series(t_acc, name="training_accuracy")
St_f1 = pd.Series(t_f1, name="training_f1")
St_kappa = pd.Series(t_kappa, name="training_kappa")
Sv_loss = pd.Series(v_loss, name="val_loss")
Sv_acc = pd.Series(v_acc, name="val_accuracy")
Sv_f1 = pd.Series(v_f1, name="val_f1")
Sv_kappa = pd.Series(t_kappa, name="val_kappa")
resultsDF = pd.concat([SeNum, St_loss, St_acc, St_f1, St_kappa, Sv_loss, Sv_acc, Sv_f1, Sv_kappa], axis=1)resultsDF.to_csv("data/models/eurosat_resnet_results.csv")resultsDF = pd.read_csv("data/models/eurosat_resnet_results.csv")plt.rcParams['figure.figsize'] = [10, 10]
firstPlot = resultsDF.plot(x='epoch', y="training_loss")
resultsDF.plot(x='epoch', y="val_loss", ax=firstPlot)
plt.show()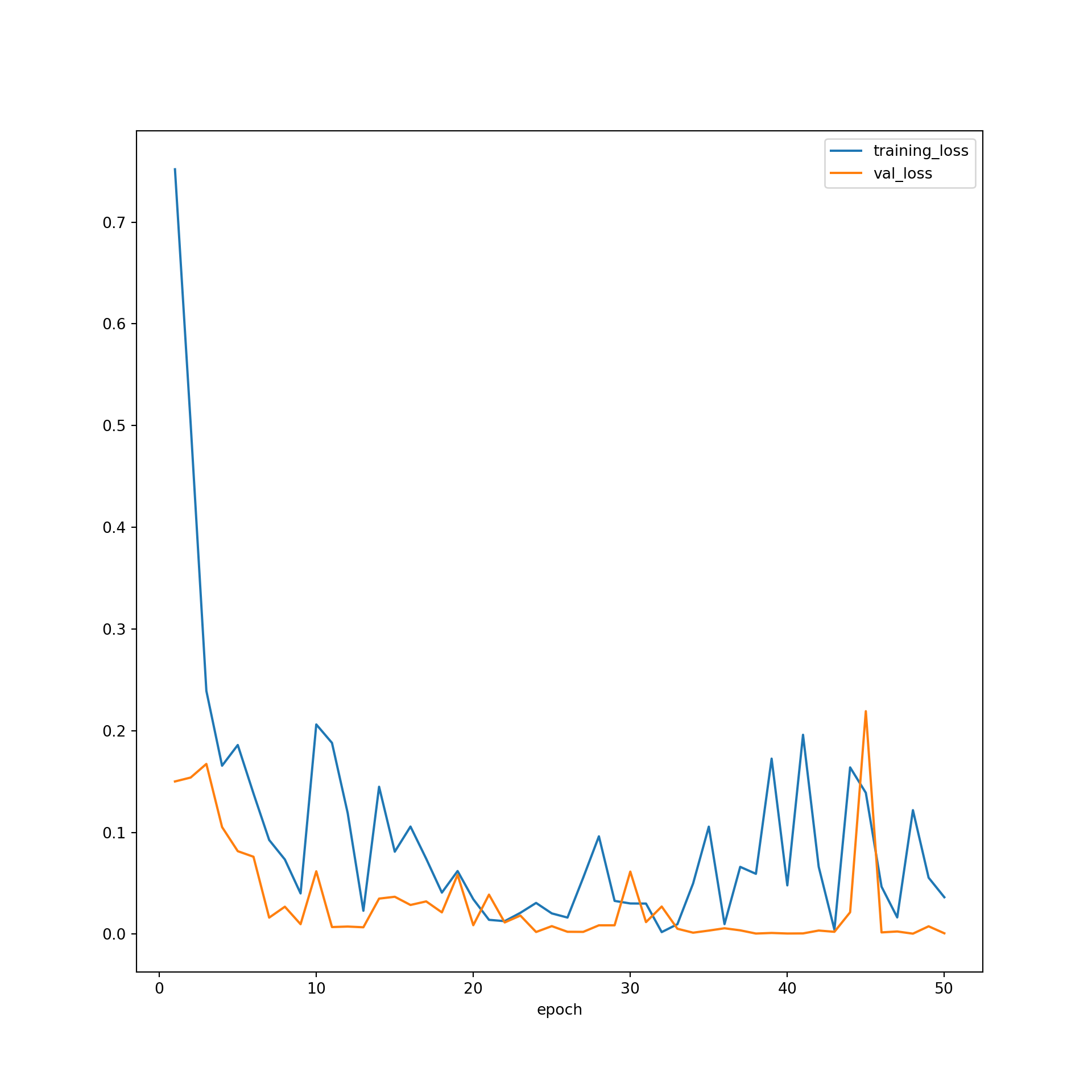
plt.rcParams['figure.figsize'] = [10, 10]
firstPlot = resultsDF.plot(x='epoch', y="training_f1")
resultsDF.plot(x='epoch', y="val_f1", ax=firstPlot)
plt.show()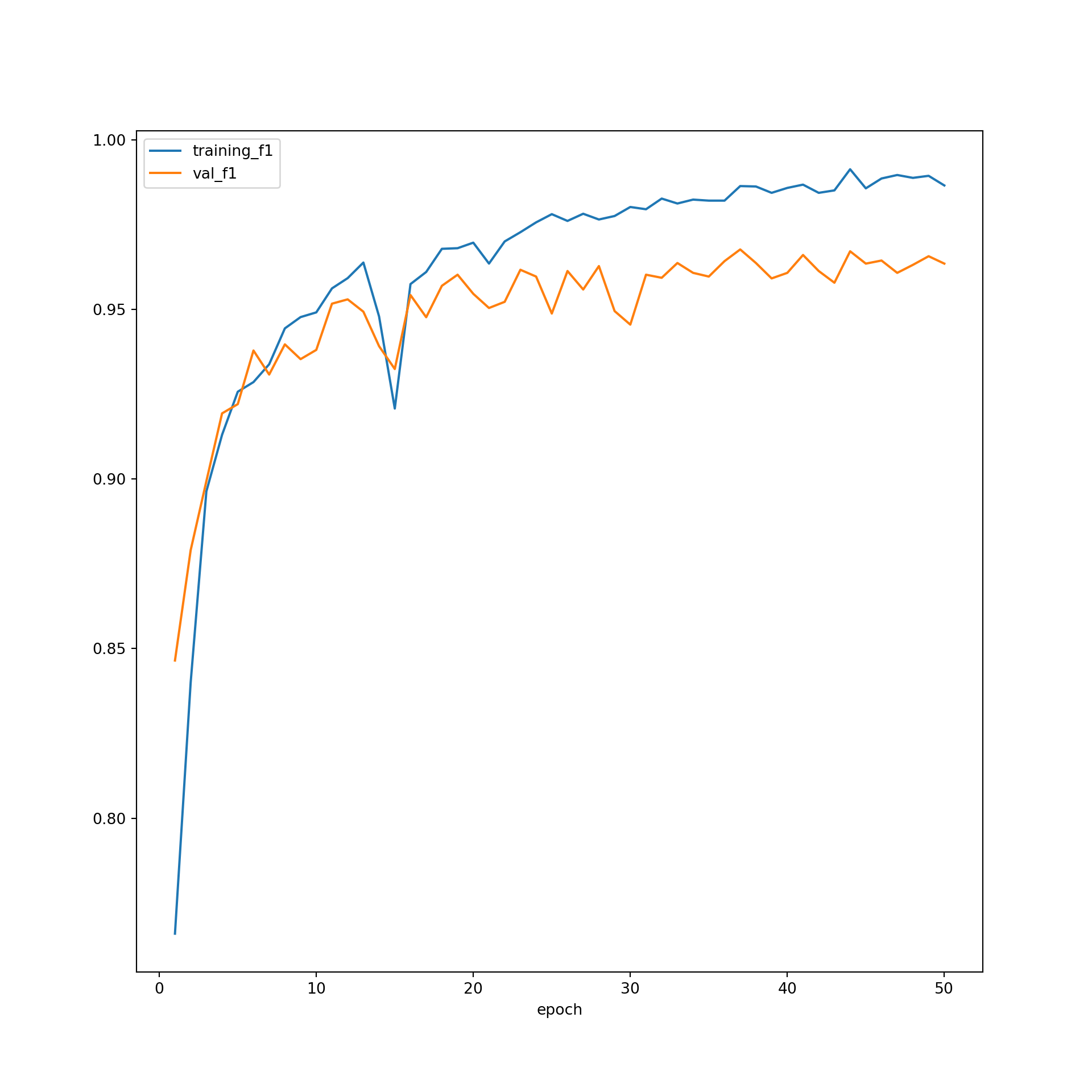
Model Assessment
I next assess the model using the withheld validation data. In order to load the saved model weights, as opposed to using the weights after the 50 training epochs, I re-instantiate an instance of the model, read in the saved weights, and load them into the model’s state dictionary. I next define a DataSet subclass and DataLoader for the testing samples. The testing samples are normalized using the band means and standard deviations of the training data, and no data augmentations or transforms are applied.
I then predict the testing data mini-batches in a loop. Again, it is important that the model be in evaluation mode so that predicting the testing data does not impact the computational graph and gradients. The metrics from torchmetrics are accumulated across mini-batches using the compute() function.
I print the assessment metrics. The results look pretty good. I achieved an overall accuracy greater than 97% for predicting to new data.
model = initialize_model(resNet="34", nChn=10, nCls=10, freeze=True, pretrained=True).to(device)best_weights = torch.load('data/models/eurosat_resnet_model.pt')
model.load_state_dict(best_weights)<All keys matched successfully>testDS = EuroSat(test, mnImg, sdImg, transform=None)testDL = torch.utils.data.DataLoader(testDS, batch_size=32, shuffle=False, sampler=None,
num_workers=0, pin_memory=False, drop_last=True)model.eval()ResNet(
(conv1): Conv2d(10, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)running_loss_v = 0.0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testDL):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss_v = criterion(outputs, targets)
accV = acc(outputs, targets)
f1V = f1(outputs, targets)
kappaV = kappa(outputs, targets)
running_loss_v = loss_v.item()
epoch_loss_v = running_loss_v/len(testDL)
accV = acc.compute()
f1V = f1.compute()
kappaV = kappa.compute()
acc.reset()
f1.reset()
kappa.reset()print(accV)tensor(0.9904, device='cuda:0')print(f1V)tensor(0.9900, device='cuda:0')print(kappaV)tensor(0.9893, device='cuda:0')print(epoch_loss_v)5.837046046508476e-07The class-level assessment metrics are obtained below.
cm = tm.ConfusionMatrix(task="multiclass", num_classes=10).to(device)
f1 = tm.F1Score(task="multiclass", num_classes=10, average="none").to(device)
recall = tm.Precision(task="multiclass", num_classes=10, average="none").to(device)
precision = tm.Recall(task="multiclass", num_classes=10, average="none").to(device)model.eval()ResNet(
(conv1): Conv2d(10, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testDL):
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
cmV = cm(outputs, targets)
f1V = f1(outputs, targets)
pV = precision(outputs, targets)
rV = recall(outputs, targets)
cmV =cm.compute()
f1V = f1.compute()
pV = precision.compute()
rV = recall.compute()
cm.reset()
f1.reset()
precision.reset()
recall.reset()print(cmV)tensor([[595, 0, 0, 0, 0, 0, 5, 0, 0, 0],
[ 0, 600, 0, 0, 0, 0, 0, 0, 0, 0],
[ 2, 1, 591, 0, 0, 2, 3, 0, 1, 0],
[ 2, 1, 0, 492, 1, 0, 0, 1, 3, 0],
[ 0, 0, 0, 0, 498, 0, 0, 1, 1, 0],
[ 2, 1, 6, 0, 0, 391, 0, 0, 0, 0],
[ 3, 0, 7, 0, 0, 0, 490, 0, 0, 0],
[ 0, 0, 1, 0, 3, 0, 0, 595, 1, 0],
[ 1, 0, 0, 1, 0, 0, 0, 0, 497, 1],
[ 1, 0, 0, 0, 0, 0, 0, 0, 1, 702]], device='cuda:0')print(f1V)tensor([0.9867, 0.9975, 0.9809, 0.9909, 0.9940, 0.9861, 0.9820, 0.9942, 0.9900,
0.9979], device='cuda:0')print(pV)tensor([0.9917, 1.0000, 0.9850, 0.9840, 0.9960, 0.9775, 0.9800, 0.9917, 0.9940,
0.9972], device='cuda:0')print(rV)tensor([0.9818, 0.9950, 0.9769, 0.9980, 0.9920, 0.9949, 0.9839, 0.9966, 0.9861,
0.9986], device='cuda:0')Concluding Remarks
The goal of this module was to explore the use of transfer learning by initializing a model architecture using parameters/weights learned from a prior dataset, in this case ImageNet, as opposed to initializing the model parameters randomly. Since this was a very different problem, I did not freeze any of the model parameters/weights. Instead, all parameters were updated during the learning process, but starting from the pre-trained parameters/weights as opposed to a random initialization.
Transfer learning can be a very powerful technique, especially when your training dataset is not large. These methods are especially useful when you are using a famous or common architecture, such as VGGNet-16 or a ResNet architecture, that has already been trained using a large dataset. As you will see in the semantic segmentation sections, these architectures, pre-trained models, and transfer learning can be used in the encoder component of semantic segmentation models. So, we will continue to explore these techniques throughout the next set of modules relating to semantic segmentation.